
Closed captions are an effective way to improve accessibility, engagement, and information retention during presentations and live events.
Automatic captions convert speech into text that shows on screen in real-time in the same language as the speech. ASR - Automated Speech Recognition - is a sort of artificial intelligence used to produce these transcripts of spoken sentences.
Word Error Rate
To evaluate the accuracy of automated captions, the most widely used metric is the Word Error Rate (WER). This measures the number of errors in the automated transcript compared to the actual words spoken by the speaker. Essentially, it provides a way to determine how well the automated system is converting speech to text.
For example, if 4 out of 100 words are wrong, the accuracy would be 96%.
The Word Error Rate (WER) is a metric used to measure the accuracy of automated captions. It aligns correctly identified word sequences at a granular level before calculating the total number of corrections necessary to fully align the reference and transcript texts. This includes identifying substitutions, deletions, and insertions. The WER is then calculated by dividing the number of adjustments needed by the total number of words in the reference text. Generally speaking, the lower the WER, the more accurate the voice recognition system.
WER overlooks the nature of errors
The WER measurement can be deceptive because it does not inform us how relevant/important a certain error is. Simple errors, such as the alternate spelling of the same word (movable/moveable), are not often regarded as errors by the reader, whereas a substitution (exemptions/essentials) might be more impactful.
WER numbers, particularly for high-accuracy speech recognition systems, can be misleading and do not always correspond to human perceptions of correctness. For humans, differences in accuracy levels between 90 and 99% are often difficult to distinguish.
| Original transcript: | ASR captions output: |
| For example, I do like only very limited use to be made of the essentials provided I would like to go into one particular point in more detail I fear that I call on individual state parliaments to ratify the convention only after the role of the European court of law has been clarified could have very detrimental effects. | For example, I too would like only very limited use to be made of the exemptions provided I would like to go into one particular point in more detail I fear that the call on individual state parliaments to ratify the convention only after the role of the European court of law has been clarified could have very detrimentl effects. |
Interprefy's Perceived Word Error Rate
Interprefy has developed a proprietary and language-specific ASR error metric called Perceived WER. This metric only counts errors that affect human understanding of the speech and not all errors. Perceived errors are usually lower than WER, sometimes even as much as 50%. A perceived WER of 5-8% is usually hardly noticeable to the user.
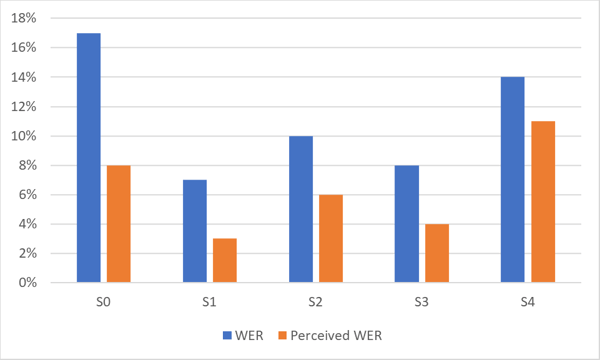
The chart below shows the difference between WER and Perceived WER for a highly accurate ASR system. Note the difference in performance for different data sets (S0-S4) of the same language.
As shown in the graph, the perceived WER by humans is often substantially better than the statistical WER.
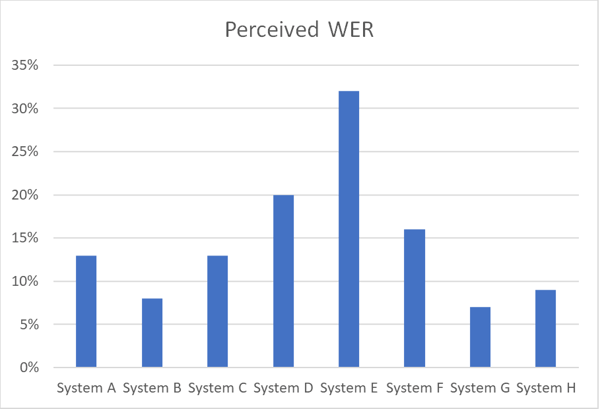
The chart below illustrates differences in accuracy between various ASR systems working on the same speech data set in a certain language using Perceived WER.
Key factors to achieve incredibly precise closed captioning
There are three key things you should consider:
- Use a best-in-class solution: Instead of choosing any out-of-the-box engine to cover all languages, go for a provider who utilises the best available engine for each language in your event.
- Optimise the engine: Choose a vendor who can supplement the AI with a bespoke dictionary to guarantee that brand names, odd names, and acronyms are appropriately captured.
- Ensure high-quality audio input: If the audio input is bad, the ASR system will not be able to achieve output quality. Make sure, the speech can be captured loud and clearly.